
(openPR) Hochverfügbarkeit sollte in modernen Rechenzentren großgeschrieben werden. Sollte! In der Realität kommt es jedoch immer wieder zu erheblichen Ausfällen von Systemen, die nicht nur zentrale kaufmännische Geschäftsprozesse sondern auch den operativen Betrieb für einen nicht absehbaren Zeitraum stören. Das führt nicht nur zu Frust bei Betreibern und Nutzern, sondern verursacht zudem hohe Kosten, die oftmals zum Zeitpunkt des Schadenseintritts noch gar nicht abschätzbar sind. Glaubt man dem Veeam Availability Report können 89 % aller Rechenzentrumsbetreiber der Forderung nach stabil laufenden Lösungen nicht gerecht werden. Gründe für Ausfälle von Rechenzentren gibt es unzählige, die häufigsten sind Stromausfälle, menschliches Fehlverhalten und Störungen auf RZ-Ebene. In Deutschland steht die IT im Schnitt alle 2 Wochen still. Laut Umfrage verzeichnen Unternehmen und Behörden hierzulande im Durchschnitt 27 ungeplante Ausfälle pro Jahr, jeder Vierte sogar über 50 Ausfälle.
Viele Betreiber werben mit einer durchschnittlichen Verfügbarkeit von 99 %. Diese Werte erreichen die meisten aller Rechenzentren. Hochgerechnet auf ein Jahr fallen Systeme so immernoch bis zu vier Tage pro Jahr aus – die dabei entstehenden Kosten sind nach wie vor enorm und erreichen in Summe nicht selten Millionenenhöhe. Rechenzentrumsbetreiber fürchten jedoch auch nicht direkt messbare Schäden, wie z. B. Imageverluste ihres Unternehmens oder ihrer Marke sowie schwindendes Vertrauen ihrer Kunden in die Infrastruktur.
Wann ist hochverfügbar tatsächlich hochverfügbar?
Definitorisch gilt ein System als hochverfügbar, wenn eine Anwendung auch im Fehlerfall weiterhin verfügbar ist und ohne unmittelbaren menschlichen Eingriff weiter genutzt werden kann. Für Nutzer sollte eine Unterbrechung also nicht oder im schlimmsten Fall nur kurz wahrnehmbar sein. Hochverfügbarkeit bezeichnet also die Fähigkeit eines Systems, bei Ausfall einer seiner Komponenten einen uneingeschränkten Betrieb zu gewährleisten. Betrachtet man die erhobenen hohen Ausfallzeiten sowie dabei entstehenden Kosten kann von Hochverfügbarkeit also kaum die Rede sein. Wie aber lässt sich die Downtime von Systemen verringern, um den notwendigen Schritt zur Hochverfügbarkeit zu gehen und Kosten für Systemausfälle drastisch zu minimieren?
Hochverfügbarkeit im Fokus von Forschungsprojekt
Dieser Thematik widmen sich unterschiedlichste Akteure im aktuell laufenden Forschungsprojekt fast realtime. In Zusammenarbeit mit der TU Dresden, der Siemens AG, Fraunhofer Instituten und der TU Chemnitz wird der Fragestellung nachgegangen, wie Latenz auf Systemebene minimiert, die Systemzuverlässigkeit gesteigert und in Folge dessen die Echtzeitfähigkeit von Sensor-Aktor-Systemen optimiert werden kann. Cloud&Heat Technologies aus Dresden, Entwickler und Produzent schlüsselfertiger, beliebig skalierbarer Rechenzentrumslösungen mit mehrjähriger Operationserfahrung einer eigenen Public Cloud, lässt als Projektpartner sein umfassendes Wissen zur Installation und den Betrieb verteilter Cloud-Infrastrukturen einfließen.
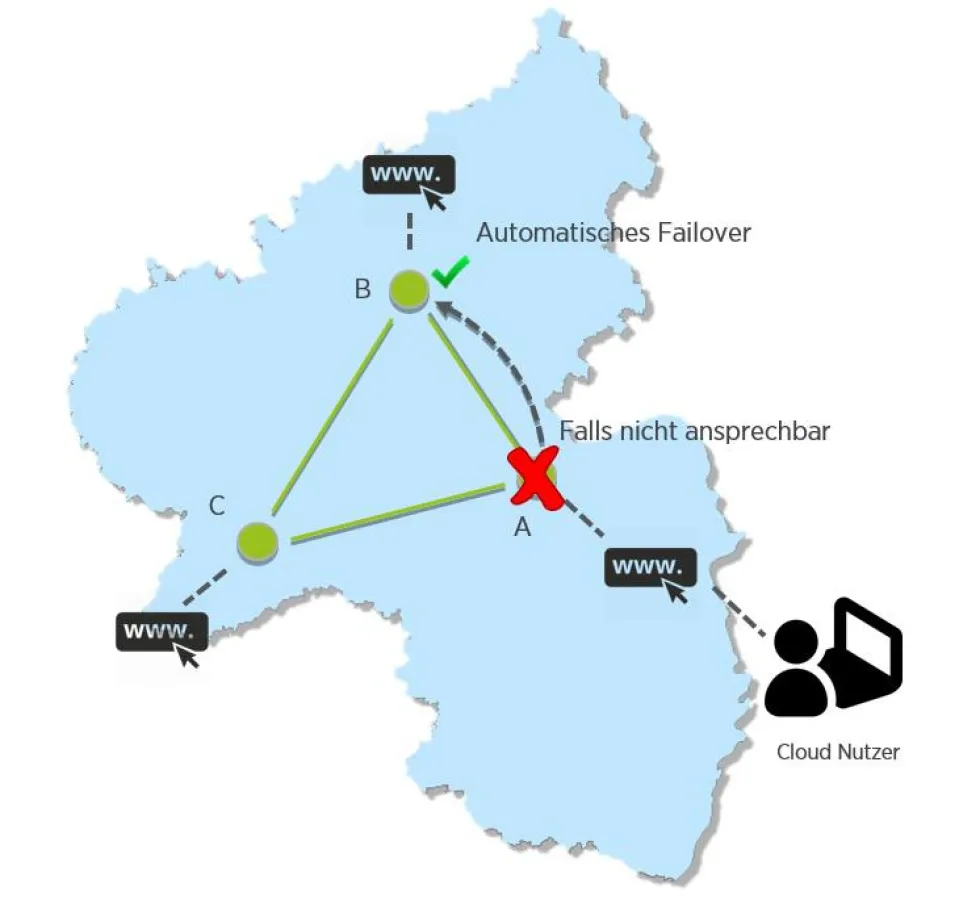
Um die Verfügbarkeit von Systemen zu erhöhen, hat Cloud&Heat im Rahmen von fast realtime zunächst zwei essentielle Nutzeranforderungen an eine hochverfügbare Cloud-Infrastruktur definiert:
Nutzeranforderung I an die Cloud: Reduzierte Ende-zu-Ende-Latenz
Zunächst soll die Latenz zwischen Nutzer und Cloud minimiert werden. Dazu entwickelte Cloud&Heat einen Geolokalisator, der ausgehend vom Nutzer softwaregesteuert denjenigen Serverstandort auswählt, auf dem der Nutzer seine Cloud Ressourcen (beispielsweise Virtuelle Maschinen) buchen kann, der die geringste Latenz aufweist.
Nutzeranforderung II an die Cloud: Niederlatente Ausfallsicherung
Weiterhin soll die Latenz zwischen den verteilten Standorten optimiert werden. Dank einer verteilten Rechenzentrumsinfrastruktur bestehend aus lokal betriebenen, kleineren Standorten, lassen sich Ende-zu-Ende-Latenzen zwischen den Standorten minimieren. Die Zeit, die benötigt wird, alle vorhandenen Daten von Standort A am redundanten Standort B zu synchronisieren und so im Falle einer Downtime in Standort B vorzuhalten wird so auf wenige Millisekunden reduziert. Ziel des Projektes ist es, die Latenzen zwischen den vorhandenen Knoten einer Infrastruktur noch weiter zu optimieren. Eine signifikant niedrige Latenz kann durch lokale Nähe zum Kunden realisiert werden, also genau dann, wenn Cloud-Nutzer aus Deutschland ihre Cloud-Ressourcen nicht in Serverfarmen in den USA starten.
Projektausblick
In der verbleibenden Projektlaufzeit von einem Jahr, arbeitet Cloud&Heat an der Zusammenführung der Ergebnisse zur Bereitstellung hochverfügbarer Systeme. Im Ergebnis wird also nicht nur die Latenz zwischen Nutzer und Standort A sowie die Latenz beim Ausfall zwischen den Standorten reduziert, sondern Nutzer können auch nach einem Ausfall Ressourcen nutzen, mit denen sie effizient und mit nicht spürbaren Verzögerungen kommunizieren können.
Die aktuellen Ergebnisse ihrer Forschung präsentieren Cloud&Heat sowie alle übrigen 79 Konsortiumsmitglieder auf dem diesjährigen fast-Clustermeeting am 16. & 17. Januar 2017 in Dresden.
Über fast realtime
fast realtime ist Basisprojekt im Förderprojekt fast (fast actuators, sensors and transceivers). fast startete 2013 und wird im Rahmen des BMBF „Zwanzig20 – Partnerschaft für Innovation“ Programmes, das sich dem Zukunftsthema innovativer Echtzeitsysteme verschrieben hat, gefördert. Insgesamt 80 Konsortiumspartner beteiligen sich.









